When reviewing my 10 year-old son’s homework, I like to show him how to do it programmatically and automating tedious math assignments gets his attention.
The assignment is in Norwegian, but basically the task at hand is to find the largest number in each cell. The most upper left cell contains the values 1,5 , 1,0555 and 1,55 (the decimal separator in Norway is comma), so the correct answer for this cell is 1,55.
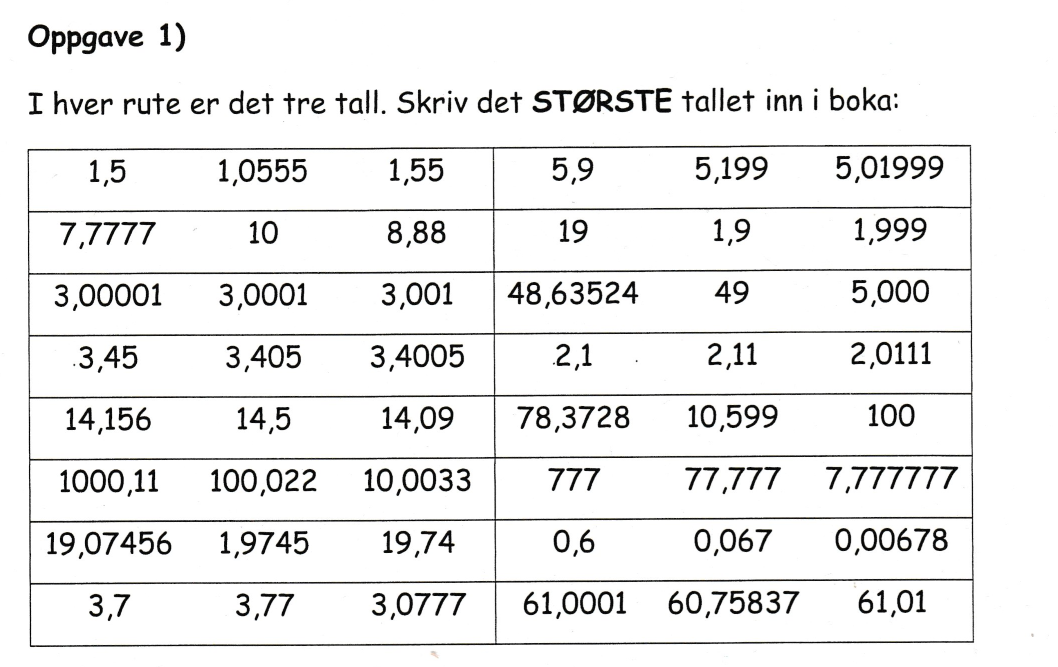
The task can be divided into two subtasks:
- Converting the image of the assignment into data the computer understands.
- Determining a cell and finding the largest number.
The process of converting an image of text into data a computer understands is called Optical Character Recognition (OCR). There are many OCR engines, but one of the more well-known ones is Tesseract, which will be our weapon of choice as it also happens to have a .NET wrapper.
Tesseract has been trained on about 4500 fonts and has data files for many languages. For this task we’ll be using the Norwegian data file, nor.traineddata. Although not important as we’re only interested in the numbers.
To use Tesseract, we initialize the engine with the path to the data file(s) and the language of choice. Next, we load and process the image before binding the result to the text identifier.
let engine = new TesseractEngine(@"./tessdata", "nor", EngineMode.Default)
let img = Pix.LoadFromFile("oppgave1.png")
let page = engine.Process(img)
let text = page.GetText();
The value of text:
Oppgave 1)
I hver ruTe er da Tre Tall. Skriv deT STØRSTE TaIIeT inn i boka:
... many blank lines ...
1,5 1,0555 1,55 5,9 5,199 5,01999
7,7777 10 8,88 19 1,9 1,999
3,00001 3,0001 3,001 48,63524 49 5,000
3,45 3,405 3,4005 2,1 2,11 2,0111
14,156 14,5 14,09 78,3728 10,599 100
1000,11 100,022 100,02 777 77,777 7,777777
19,07456 1,9745 19,74 0,6 0,067 0,00678
3,7 3,77 3,0777 61,0001 60,75837 61,01
Apart from the many blank lines, Tesseract gracefully handled the table layout, but it’s apparent that Tesseract hasn’t been trained with the font in question as words are off and there are capitalization issues. Luckily we’re only concerned with the numbers and they all look good.
The blank lines are either empty or contain a single whitespace. We remove these and skip the 2 lines containing text before parsing each line (row) individually and finally writing out the result.
text.Split([| "\n" |], StringSplitOptions.RemoveEmptyEntries)
|> Array.filter (fun line -> line <> " ")
|> Array.skip 2
|> Array.map parseLine
|> printfn "%A"
Each line contains 6 numbers separated by a whitespace, e.g. 1,5 1,0555 1,55 5,9 5,199 5,01999. We map these to decimals and return a tuple containing the largest value in the left column (the first 3 numbers) and the largest value in the right column (the last 3 numbers).
let parseLine (line : String) =
let values = line.Split(' ') |> Array.map (fun value -> Convert.ToDecimal(value, CultureInfo("no-nb")))
let left = values |> Array.take 3 |> Array.max
let right = values |> Array.skip 3 |> Array.max
(left, right)
The result:
[|(1.55M, 5.9M);
(10M, 19M);
(3.001M, 49M);
(3.45M, 2.11M);
(14.5M, 100M);
(1000.11M, 777M);
(19.74M, 0.6M);
(3.77M, 61.01M)|]
Wrapping Up
My son was impressed and so too was I that it could be accomplished with so little code. The entire code is available as a F# script and also included a repository with everything required for running the script.
After writing the blog post, I submitted an abstract based on the blog post to NDC Oslo and was fortunate enough to be accepted. The talk is available on YouTube: